Easy Embeddings Indexing Pipelines with Redpanda and Neon
Take a stream of data, compute embeddings of each message, and store them in Postgres on Neon

Building high throughput, scalable embeddings indexing pipelines can be a daunting task, often requiring stitching together systems with code that needs to scale, handle failures and ensure delivery guarantees. However, with powerful tools like Redpanda and Neon, this process can be significantly simplified.
In this blog post, we walk through how to set up an embeddings indexing pipeline using these technologies, without the need for any code. This streamlined approach leverages Redpanda for data ingestion and Neon for efficient indexing and querying all in a managed environment. Neon is a scalable, serverless postgres database with support for vector similarity search using pgvector. Combined with Redpanda, a unified streaming data platform that is blazing fast and simple to manage, we can create an embedding indexing pipeline that checks all the boxes without needing to write any code.
Setting up an embeddings indexing pipeline
Prerequisites:
- Latest version of Redpanda Connect
- Redpanda Serverless Cluster
- Neon Postgres Database
As a warm up, you can check out Neon’s blog post on building a Retrieval-Augmented Generation (RAG) applications with Neon and pgvector. In this post, we’ll demonstrate a way to create a high throughput, scalable embeddings indexing pipeline for RAG applications using Redpanda Connect.
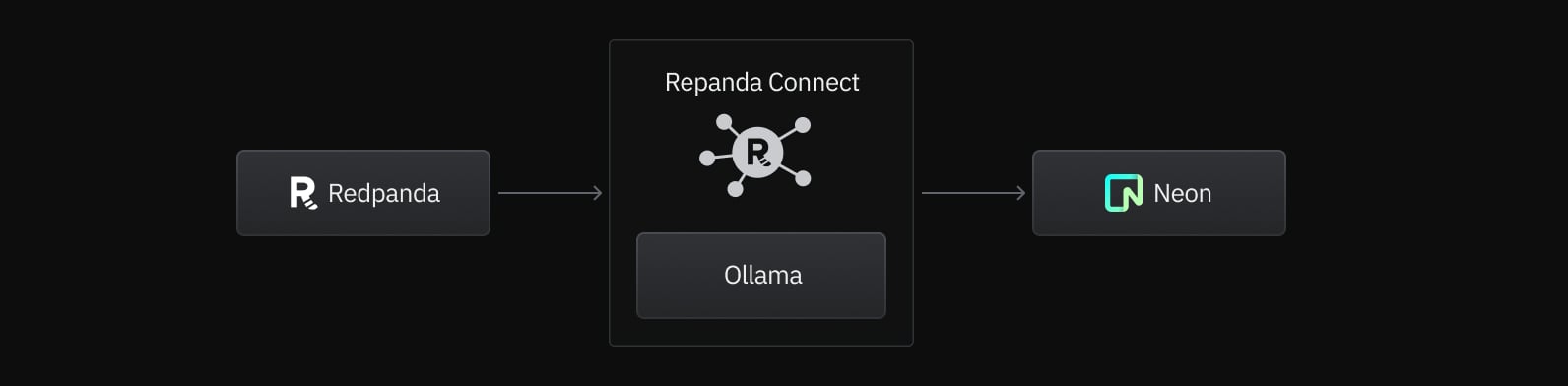
Step 1. Understand our data
The data we have for the pipeline will be invoices from an ecommerce application. We want to index what the customer bought so that they can search their past purchases using natural language. The data has the following form:
{
"InvoiceNo": 536368,
"Country": "United Kingdom",
"CustomerID": 13047,
"Date": "12/1/2010 8:34",
"Items": [
{
"StockCode": 22960,
"Description": "JAM MAKING SET WITH JARS",
"Quantity": 6,
"UnitPrice": 4.25
},
{
"StockCode": 22913,
"Description": "RED COAT RACK PARIS FASHION",
"Quantity": 3,
"UnitPrice": 4.95
},
{
"StockCode": 22914,
"Description": "BLUE COAT RACK PARIS FASHION",
"Quantity": 3,
"UnitPrice": 4.95
}
]
}We’ll be using Redpanda as our intermediate buffer between producers and the computation of embeddings for Neon. Redpanda’s compatibility with the Apache Kafka® protocol means you can produce language easily with a client library in your favorite programming language, and easily absorb spikes in traffic or any pauses in the downstream processing.
Step 2. Read data from Redpanda
Reading this data in Redpanda brokers using Redpanda Connect is a matter of defining the connection in YAML:
input:
kafka:
addresses: ["${RP_CLUSTER}.any.us-east-1.mpx.prd.cloud.redpanda.com:9092"]
topics: ["invoices"]
consumer_group: "connect-embeddings-index-pipeline"
tls: {enabled: true}
sasl:
mechanism: SCRAM-SHA-256
user: ${RP_USER}
password: ${RP_PASS}Step 3. Compute embeddings using Ollama
Next we need to actually set up our data processors within Redpanda Connect, we will do some small transformations of the data using bloblang, compute the embeddings locally using Ollama, then flatten the array into many messages using unarchive.
pipeline:
processors:
- label: compute_embeddings
branch:
request_map: |-
let Description = this.Items.map_each(item -> "%d of %s".format(item.Quantity, item.Description)).join(", ")
root = "search_document: The order contained %s".format($Description)
processors:
- ollama_embeddings:
model: nomic-embed-text
result_map: |-
root.embeddings = this
- label: flatten_items
mapping:
root = this.Items.map_each(item -> item.merge(this.without("Items")))
- label: seperate_items
unarchive:
format: json_arrayStep 4. Write output into Neon
Finally we can insert the data into Neon and make it queryable:
pipeline:
processors:
- label: compute_embeddings
branch:
request_map: |-
let Description = this.Items.map_each(item -> "%d of %s".format(item.Quantity, item.Description)).join(", ")
root = "search_document: The order contained %s".format($Description)
processors:
- ollama_embeddings:
model: nomic-embed-text
result_map: |-
root.embeddings = this
- label: flatten_items
mapping:
root = this.Items.map_each(item -> item.merge(this.without("Items")))
- label: seperate_items
unarchive:
format: json_arrayNow in a few dozen lines of configuration we have a full production-ready indexing pipeline using a Redpanda Cloud Serverless cluster and a Neon database.
Say hello to streamlined data processing workflows
With Redpanda and Neon, setting up a high throughput, scalable embeddings indexing pipeline has never been easier. In this post, we showed how to create a robust pipeline using these tools without writing any code. Redpanda’s Kafka compatibility ensures smooth data ingestion and handling, while Neon’s serverless Postgres architecture and pg_vector extension provide efficient storage and querying of embeddings.
This setup simplifies the process of building indexing pipelines, making them scalable and high-performing. Whether you’re indexing e-commerce transactions, customer reviews, or any other data type, this solution can handle large volumes and support your vector search query needs.
To give it a try in your own projects, sign up for Redpanda Serverless and get a free Neon Postgres account and start building!