Postgres 17 is Now Available on Neon
Spin up a PG 17 database in seconds and test the new features

Postgres 17 is out today, and we’re here for it. In keeping with our version policy, the latest major version is now available for all Neon users including those on the Free plan. Get your Postgres 17 database and start exploring the latest features immediately.
How to speed run Postgres 17 on Neon
Step 1: Create a Neon account. We only need your login info (no credit card).

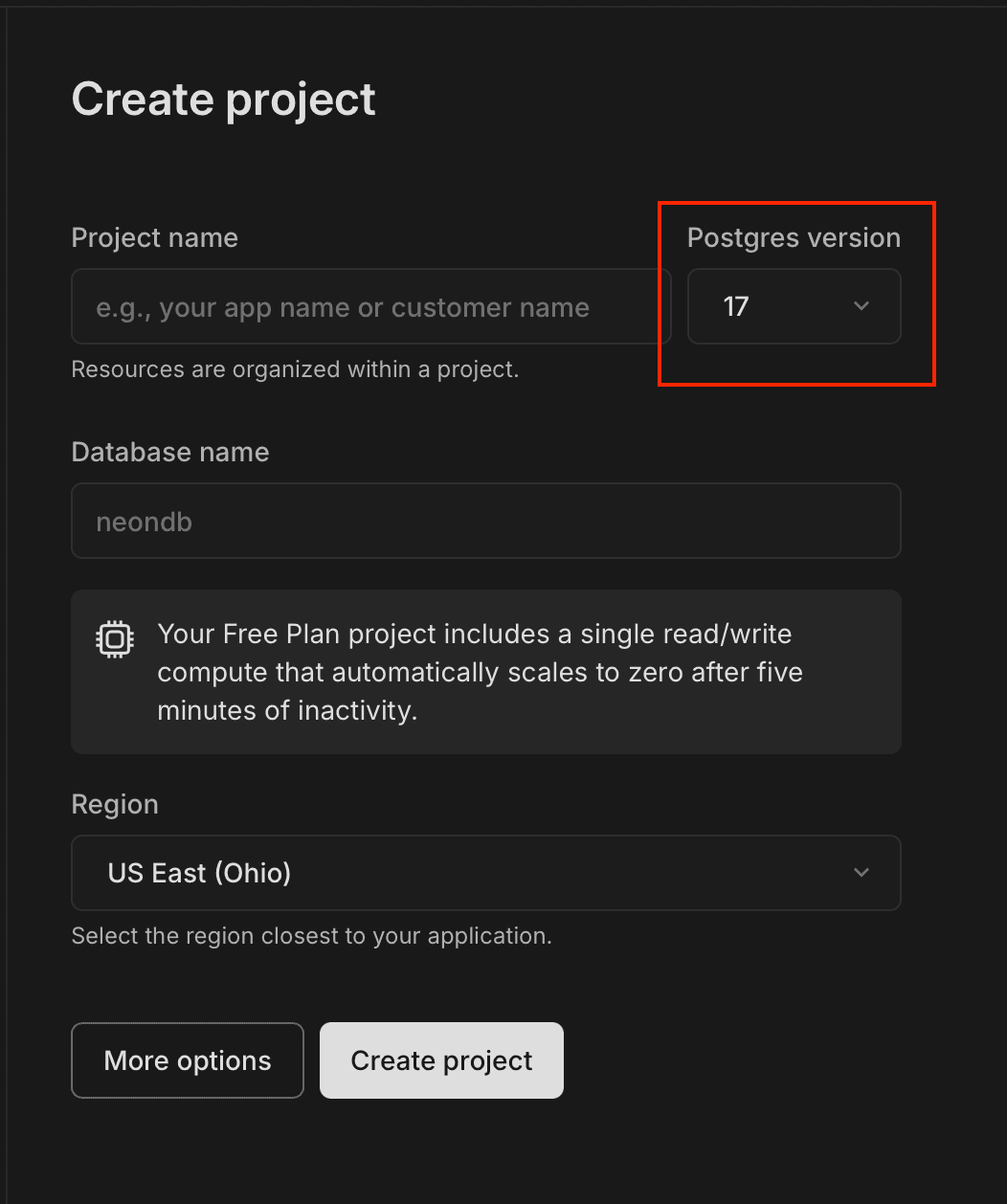
Step 2: Select `Postgres 17` for your project
Step 3: That’s it. Your Postgres 17 database is already up and running. You can start querying directly from the Neon SQL Editor or connecting with psql.

Testing new PG 17 features
Simplifying queries using MERGE with RETURNING
One of the things we’re most excited about Postgres 17 is how it improves the functionality of the MERGE command by adding RETURNING clause support. Why this matters:
- It streamlines queries. You can conditionally insert, update, or delete records without writing multiple queries.
- You get the results of the operation instantly – this is especially useful for application logic that depends on the outcome.
To quickly test it, create a sample table:
CREATE TABLE heroes (
id SERIAL PRIMARY KEY,
first_name TEXT,
last_name TEXT,
hero_name TEXT UNIQUE
);Use the MERGE command with RETURNING:
MERGE INTO heroes AS h
USING (VALUES ('Wade', 'Wilson', 'Deadpool')) AS v(first_name, last_name, hero_name)
ON h.hero_name = v.hero_name
WHEN MATCHED THEN
UPDATE SET first_name = v.first_name, last_name = v.last_name
WHEN NOT MATCHED THEN
INSERT (first_name, last_name, hero_name)
VALUES (v.first_name, v.last_name, v.hero_name)
RETURNING merge_action(), *;Output will look like this:
| merge_action | id | first_name | last_name | hero_name |
| INSERT | 1 | Wade | Wilson | Deadpool |
What is happening:
- The MERGE command checks if a hero with the hero_name ‘Deadpool’ exists.
- If matched, it updates the existing record’s first_name and last_name.
- If not matched, it inserts a new record into the heroes table.
- RETURNING merge_action() returns the action performed (INSERT or UPDATE) and the full row data.
Generating random integers with the improved random() function
Another great addition in Postgres 17 is the improvement of the random() function to accept range parameters, allowing it to generate random integers within a specified range. You can use the random(min, max) function to generate a random integer between min and max, inclusive:
SELECT random(1, 10) AS random_number;random_number
---------------
7
(1 row)Generating random numbers directly within Postgres is useful for many things, for example creating test data—you could use random() to populate existing tables with random values as you run some tests. For example, consider these two tables, with student names and scores:
CREATE TABLE students (
id SERIAL PRIMARY KEY,
name TEXT
);
INSERT INTO students (name) VALUES
('Alice'),
('Bob'),
('Charlie'),
('Diana'),
('Ethan');CREATE TABLE test_scores (
student_id INT,
score INT
);The test_scores table is still empty, but you could insert test scores for every student:
INSERT INTO test_scores (student_id, score)
SELECT
s.id,
random(50, 100)
FROM
students s;And when you query the table, you should see random values:
SELECT
ts.student_id,
s.name,
ts.score
FROM
test_scores ts
JOIN students s ON ts.student_id = s.id;| student_id | name | score |
| 1 | Alice | 78 |
| 2 | Bob | 92 |
| 3 | Charlie | 85 |
| 4 | Diana | 67 |
| 5 | Ethan | 74 |
Another nice thing you can do is to combine random() with generate series() for creating bulk data without an existing `students` table, e.g.:
INSERT INTO test_scores (student_id, score)
SELECT
generate_series(1, 1000) AS student_id,
random(50, 100)
;What’s would happen here:
- generate_series(1, 1000) would generate numbers from 1 to 1000, simulating 1000 students.
- random(50, 100) would assign a random score to each simulated student.
Querying JSON data with JSON_TABLE
Postgres 17 also introduces JSON_TABLE, a feature that simplifies working with JSON data by transforming it into a relational format. You can query and manipulate JSON structures as if they were regular tables. How it works is straightforward—for example, imagine you have this array:
WITH json_data AS (
SELECT '[
{"product": "Laptop", "details": {"price": 1200, "stock": 25}},
{"product": "Smartphone", "details": {"price": 800, "stock": 50}},
{"product": "Tablet", "details": {"price": 500, "stock": 40}}
]'::JSON AS data
)To transform this data into a relational table, you’d run:
SELECT *
FROM json_data,
JSON_TABLE(
json_data.data,
'$[*]' COLUMNS (
product_name TEXT PATH '$.product',
price INT PATH '$.details.price',
stock INT PATH '$.details.stock'
)
) AS jt;It would transform it into a table like this:
| product_name | price | stock |
| Laptop | 1200 | 25 |
| Smartphone | 800 | 50 |
| Tablet | 500 | 40 |
If you had an existing products table with a JSONB column…
CREATE TABLE products (
id SERIAL PRIMARY KEY,
details JSONB
);
INSERT INTO products (details) VALUES
('{"product": "Headphones", "details": {"price": 150, "stock": 100}}'),
('{"product": "Speaker", "details": {"price": 300, "stock": 60}}');…you could use JSON_TABLE to query the data together:
SELECT p.id, jt.*
FROM products p,
JSON_TABLE(
p.details,
'$' COLUMNS (
product_name TEXT PATH '$.product',
price INT PATH '$.details.price',
stock INT PATH '$.details.stock'
)
) AS jt;Reducing connection latency with sslnegotiation=direct
A nice one: Postgres 17 introduces the sslnegotiation connection parameter, which allows clients to control how SSL negotiation is handled when establishing a connection. By using the sslnegotiation=direct option, you can reduce the latency of establishing a secure connection by skipping unnecessary negotiation steps.
At Neon, we’ve implemented support for sslnegotiation=direct within our proxy layer. This means that even if your database is running an older version of Postgres, you can still take advantage of faster connection times when using a Postgres 17 client with this option.
Let’s demo it:
Before
Without specifying the sslnegotiation parameter, the client and server engage in an initial negotiation to determine if SSL is required, which adds extra round trips and increases connection time:
$ time psql "postgresql://neondb_owner@your-neon-endpoint/neondb?sslmode=require" -c "SELECT version();"
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 16.4 on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
(1 row)
real 0m0.872s
user 0m0.019s
sys 0m0.000sAfter
By adding sslnegotiation=direct to your connection string, the client skips the initial negotiation and directly initiates an SSL connection, reducing the overall connection time:
$ time psql "postgresql://neondb_owner@your-neon-endpoint/neondb?sslmode=require&sslnegotiation=direct" -c "SELECT version();"
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 17.0 on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
(1 row)
real 0m0.753s
user 0m0.016s
sys 0m0.005sGetting insights into memory usage via EXPLAIN
The last one. Postgres 17 comes with an enhancement to the EXPLAIN command by allowing it to report the memory usage of the query planner during the preparation of execution plans. This gives you information about the resources consumed during query planning, helping you identify queries that consume excessive memory during the planning phase.
In Postgres 17, the EXPLAIN output includes a summary section that reports the memory usage of the optimizer during the planning phase:
QUERY PLAN
Nested Loop (cost=... rows=... width=...) (actual time=... rows=... loops=...)
Output: cv1.id, cv1.data, cv2.id, cv2.data
Join Filter: (cv1.data <> cv2.data)
...
Planning Time: 123.456 ms
Planning Memory Usage: 10,240 kB
Execution Time: 789.012 msThe new line Planning Memory Usage: 10,240 kB tells you memory consumed by the optimizer during the planning phase.
Upgrading to Postgres 17
While minor version upgrades in Neon happen automatically, there is still manual work necessary to upgrade major versions. If you want to test moving an existing database running an older major version of Postgres to 17, follow the steps outlined in our upgrading your Postgres version guide. If you are using any extensions, be sure to check extension support for Postgres 17 on Neon before upgrading.
Get started with Postgres 17
Start here to create a free Neon account with Postgres 17 ready to go. We’re on Discord if you have any questions.